Why computers don't understand English
English is hard, complicated, confusing, and a lot of other things. Computers don't operate well under that.
We have to face the facts. English is hard. And complicated. And confusing. And a lot of other things.
One of the more interesting books I've read in the last few years was a history of the evolution of the English language: The Mother Tongue - English And How It Got That Way. Bill Bryson's opening paragraph is, to this day, my favorite description of the English language.
More than 300 million people in the world speak English and the rest, it sometimes seems, try to. It would be charitable to say that the results are sometimes mixed.
The complications of the English language are well-known and well-documented. It frustrates the native and secondary speakers alike. You may have heard of y'all'd've, but what about y'all'd've'f'i'd've? How about it's what it's? The fact we can abuse contractions in such a twisted manner is both funny and a testament to how convoluted English really is.
So if English is difficult for humans to understand, the (unintentional) creators of the language, how much more difficult do you think it is for computers, mere electrical signals pulsing through rocks, metals, and other precious materials that we have cast a dark spell upon and tricked into guessing that 1 + 1 = 2?
That answer, just like English, is complicated.
Knowing we understand
To fairly answer this question, we first need to define what it means to "understand" English. Dictionary.com provides many definitions, a couple of which happens to align with my definition.
to perceive the meaning of; grasp the idea of; comprehend
to be thoroughly familiar with; apprehend clearly the character, nature, or subtleties of
to assign a meaning to; interpret
to perceive what is meant; grasp the information conveyed
That last definition is especially applicable here and what we will focus on. Given both the spoken and written English language, how accurately do computers perceive what is meant (the intention) by a statement and how correctly do they interpret the application of a statement?

Everything is arbitrary
As much as we don't want to think about it or admit it, all spelling and grammar rules are arbitrary and made up. Writers, editors, and linguists sometimes like to play gatekeeper to prevent... inferior words and phrases from entering the vernacular, as if it is their sacred duty to protect their Majesty, the Formal and Proper Rules of Written and Spoken English. Their crusades are relentless. I guarantee I made someone cringe with my short-list of abused contractions. I remember when Oxford declared the "Face with Tears of Joy" emoji, 😂, to be the 2015 word of the year. People were not happy. Why? The most common complaint I heard was "An icon is not a word!!!"

As I said, it's almost as if all of these language rules are made up.
The existence of intuition
The complete arbitrariness of the written and spoken language is something computers... just don't handle well. Computers have a hard time understanding language, period. Even with advances in machine learning (ML) and artificial intelligence (AI), computers still handle the meanings of the spoken and written language very poorly. For example, take the slang phrase "bombed it." At any given time, this phrase can refer to:
- literally bombing something
- doing something very well
- doing something very poorly
How do we know the intended meaning? We determine it through this thing called intuition. Dictionary.com provides the following linguistic definition for intuition:
The ability of the native speaker to make linguistic judgments, as of the grammaticality, ambiguity, equivalence, or nonequivalence of sentences, deriving from the speaker's native-language competence.
I like Brené Brown's definition from her book The Gifts of Imperfection:
Intuition is the rapid-fire, unconscious associating process — like a mental puzzle. The brain makes an observation, scans its files, and matches the observation with existing memories, knowledge, and experiences. Once it puts together a series of matches, we get a "gut" on what we've observed.
These two definitions are not contrary to each other. In fact, they are complimentary. Brown's version provides the psychological grounding for the linguistic application. As the brain performs pattern matching and links new data to existing information to provide context and understanding, our ability to correctly interpret words, phrases, sentences, and icons increases, regardless of their nuance, abstraction, ambiguity, or concreteness. Even our ability to sympathize and empathize with others over issues and problems improves over time because we understand the intention and expression of the words they are using to discuss it. When we do not understand something though immediate intuition, we ask for clarification.
Computer literally cannot do this. They have no capacity for intuitive thought. Yes, we have the science, study, and methodology of sentiment analysis to help guess what is going on, but it really is just a guess. ML and AI work best when they are trained on examples (called models) that are representative of the writing that is to be analyzed. Their ability to accurately interpret a statement's meaning drops significantly with data that doesn't match the training models. They can only "match" new data as well as they can "understand" the existing information. Nuance throws off its ability so much that it can occasionally lead to seemingly political conclusions. Notice that they also must be trained using an externally provided library source. People build this library naturally, consciously and subconsciously, throughout their lifetimes.
This doesn't mean humans fully agree on a statement's intended meaning. Anyone who has taken a writing class in high school and/or higher education knows of the infamous "blue curtains" dilemma. The speaker in a writing references some curtains in the room that are blue. What is the meaning behind the reference? It could be that the speaker is depressed and the curtains are representative of their current emotional status. It could also mean that the writer just needed a dang color and blue was the first color that came to mind. Robert Frost's "The Road Not Taken" is a great example of the inability of people to agree on meaning. Frost clearly stated that it is an ironic piece that jabs at a fellow writer friend but had been taken "pretty seriously … despite doing my best to make it obvious by my manner that I was fooling."
However, despite our inability to agree on meanings, we generally agree on things more commonly and accurately than a computer can extract the meaning.
(Un)ordered writing
While everything we have discussed so far applies generally to computers attempting to extract intended meaning from the English language, the issues are more pronounced when working with the spoken language The situation with the written language, however, is slightly better. For starters, the grammar and syntax of the written language tends to be more defined. While there is still variety, ambiguity, inconsistency, and evolution, merely extracting words and phrases from the written form without interpretation is much easier for computers to accomplish. Computers excel at direct, straight-forward pattern matching and do so much better than humans. A computer can and will pick out every hashtag a Twitter user has used or every instance of a word that contains the letter "e." These are all mathematical operations, something computers were originally created for and will almost always do faster and more accurately than the human mind.
This doesn't mean a computer's ability to understand the written form of English is equally as good.
In computing, there are three major types of data: structured, semi-structured, and free-form. Structured data has a strict definition. Data must be written a certain way and is easily checked for accuracy against a standard specification. Semi-structured data has a defined structure but is not as strict. It has variety in how it is written. Free-form data has no defined form and be written however which way is desired.
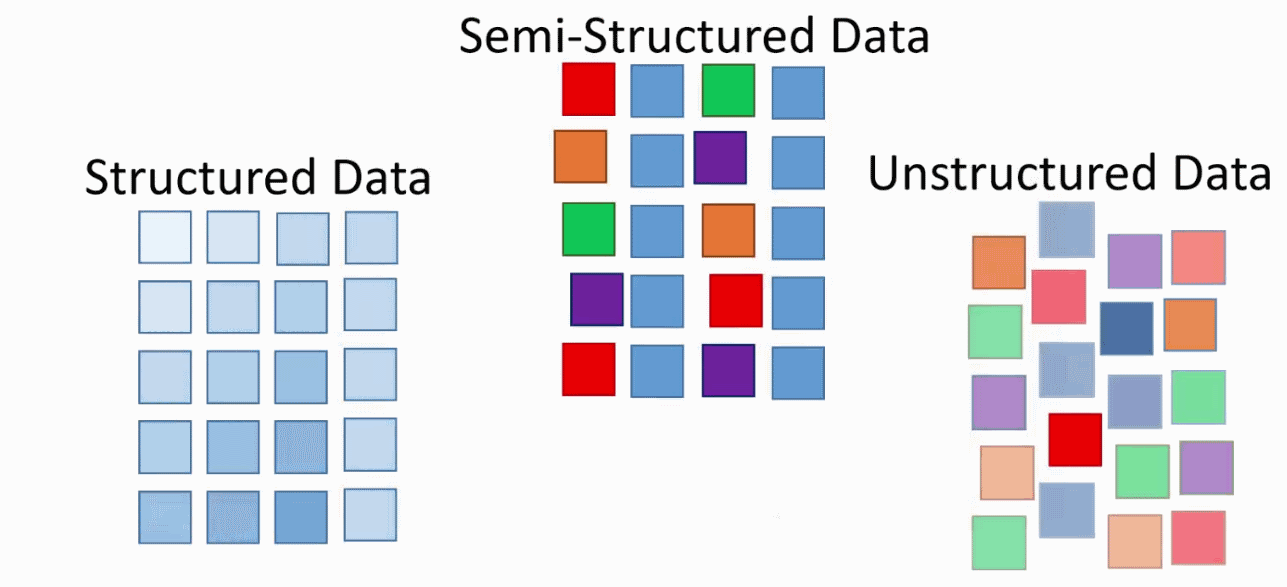
Computers work best with structured data and progressively get worse with semi-structured and free-form (or unstructured) data. Being able to read and make sense of semi-structured and free-form data is a hot topic in computing right now because there is a lot of it. If a company has the ability to successfully convert these data formats into understandable structured data, they are considered to hold a competitive market advantage.
The written word falls somewhere between semi-structured and free-form data. Even though English has a formal (yet arbitrary) set of rules that dictate how sentences should be written, they can be broken at will. These rules also evolve over time.
It's been repeatedly shown that the Millennial and younger generations tend to send text and digital messages that lack ending punctuation marks. I know I do it. If a period is included, the message has a greater chance of being interpreted in many different tones, including anger, reluctance/hesitancy, insincerity, or extra serious. The gender of the writer sending the message can also influence how the recipient may interpret the intention. Meanwhile, question marks are often reserved for rhetorical questions or obviously answered questions rather than used to indicate actual questions. Further, depending on where there are asked in the message, actual questions may also lack end punctuation. These variations in the written language are interpreted and mostly understood by humans because of (here it is again) our ability to think intuitively.
And yet again, because computers lack intuitive thinking, such arbitrariness in the written language also trips them up. Granted, it is still easier to work with. We have multiple databases containing effectively every known English letter and word ever created and used (including some we don't use anymore, like the thorn or forsooth). We have the ability to store and archive all digital text, split it up, and derive all kinds of usage statistics and make implications about the text's meanings. As mentioned already, AI and ML must have training data and when given enough, a decent enough inference job can be performed. Yet it is still limited in full comprehension because of the nuance and ambiguity of English.
Conclusion
So where does this leave us in regards to our original question of how accurately do computers perceive what is meant by a statement and how correctly do they interpret the application of a statement? Are computers ever going to fully comprehend English and be just as fluent in communication with humans which will eventually lead to the robot uprising and digital apocalypse which will be the death of all human life as we know it, just as depicted in the movies?
My opinion is an emphatic "no." Robot uprisings like that are not going to happen, nor are robots ever going to reach that level of sophistication (regardless of how cool/close it seems Boston Dynamics is getting with their latest robots). If you've read this whole post, you know the why already because I've said it multiple times over: it all comes back to lack of intuition.
Without intuitive thought, computer's cannot have fluid conversations or full comprehension. They will not be able to determine justice in disputes. They will not be able to make ethical decisions. They will not be able to move around obstacles and objects as fluidly as humans. They will only ever be able to respond as intelligently as they have been programmed. Ars' description of the Atlas robot's ability to navigate obstacles bears the point.
Atlas' movement is now driven by perception. Previously, the robot only did pre-programmed parkour on a flat surface or stationary boxes, but Atlas is now detecting the environment...and reacting to it. As the blog post puts it, "This means the engineers don't need to pre-program jumping motions for all possible platforms and gaps the robot might encounter. Instead, the team creates a smaller number of template behaviors that can be matched to the environment and executed online." Three on-board computers handle all the computation needed to perceive the world around Atlas, plot a course, and keep the robot upright.
The team doesn't have to pre-program every motion anymore, but rather movement patterns. Patterns are the very things computers are good at. Without strict patterns, things don't work. And strict patterns are exactly what the English language lacks.
This doesn't mean interaction with computer's natural language processing abilities is always going to suck. It's getting better all the time. Apple's Siri, Amazon's Alexa, Google's Assistant are light years better than they were even five years ago. But what it does mean is it's comprehension skills will always be limited, regardless of the written or spoken form. It's why we have to recognize the proper place and purpose of technology: as an assistant to humans. It's not going to replace writers, linguists, judges, assistants, analysis, and a plethora of other occupations. We may have better human-computer interactions but they will never be as fluid, diverse, confusing, ambiguous, or beautiful as human communication using a language created through our own neuro-diverse and intuitive minds.